
Thanks for becoming a member of us for yet one more session of this sequence on Raspberry Pi programming. Within the previous tutorial, we created a pi-hole advert blocker for our residence community utilizing raspberry pi 4. We additionally discovered the right way to set up pi-hole on raspberry pi 4 and the right way to entry it in any method with different gadgets. This tutorial will implement a speech recognition system utilizing raspberry pi and use it in our challenge. First, we are going to be taught the basics of speech recognition, after which we are going to construct a sport that makes use of the person’s voice to play it and uncover the way it all works with a speech recognition package deal.
Right here, you will be taught:
- The fundamentals of voice recognition
- On PyPI, what packages could also be discovered?
- Make the most of the SpeechRecognition package deal with a variety of helpful options.
Elements
- Raspberry pi 4
- Microphone


A Temporary Overview of Speech Recognition
Are you interested by the right way to incorporate speech recognition right into a Python program? Nicely, in terms of conducting voice recognition in Python, there are some things it’s good to know first. I am not going to overwhelm you with the technical specifics as a result of it could take up a complete e-book. Issues have gone a great distance in terms of fashionable voice recognition applied sciences. A number of audio system will be acknowledged and have in depth vocabulary in a number of languages.
Voice is the primary factor of speech recognition. A mic and an analog-to-digital converter are required to show speech into an digital sign and digital knowledge. The audio will be transformed to textual content utilizing varied fashions as soon as it has been digitized.
Markov fashions are utilized in most fashionable voice recognition applications. It’s assumed that audio alerts will be fairly represented as a stationary sequence when seen over a brief timescale.
The audio alerts are damaged into 10-millisecond chunks in a traditional HMM. Every fragment’s spectrogram is transformed into an actual quantity known as cepstral coefficients. The scale of this cepstral would possibly vary from 10 to 32, relying on the system’s accuracy. These vectors are the top product of the HMM.
Coaching is required for this calculation as a result of the voice of a phoneme adjustments based mostly on the supply and even inside a single utterance by the identical individual. Probably the most possible phrase to supply the desired phoneme sequence is decided utilizing a selected algorithm.
This whole course of might be computationally pricey, as one would possibly anticipate. Earlier than HMM recognition, characteristic transformations and dimension discount strategies are employed in lots of present speech recognition applications. Additionally it is doable to restrict an audio enter to solely these elements that are possible to incorporate speech utilizing voice detectors. Because of this, the recognizer doesn’t need to waste time learning sections of the sign that are not related.
Selecting a Speech Recognition Software
There are a couple of speech recognition packages in PyPI. There are a couple of examples:

NLP can discern a person’s goal in a few of these applications, which matches past easy speech recognition. A number of different providers are centered on speech-to-text conversion alone, akin to Google Cloud-Speech.
SpeechRecognition is probably the most user-friendly of all of the packages.
Voice recognition necessitates audio enter, which SpeechRecognition makes a cinch. SpeechRecognition will get you in control in minutes quite than requiring you to jot down your code for connecting mics and decoding audio information.
Because it wraps a wide range of widespread speech utility programming interfaces, this SpeechRecognition package deal presents a excessive diploma of extensibility. The SpeechRecognition library is a unbelievable alternative for each Python challenge due to its flexibility and ease of utilization. The APIs it encapsulates could or could not have the ability to assist each characteristic. For SpeechRecognition to function in your state of affairs, you will must analysis the assorted decisions.
You’ve got determined to present SpeechRecognition in the past, and now it’s good to get it deployed in your setting.
Speech Recognition Software program Set up
Utilizing pip, it’s possible you’ll arrange Speech Recognition software program within the terminal:
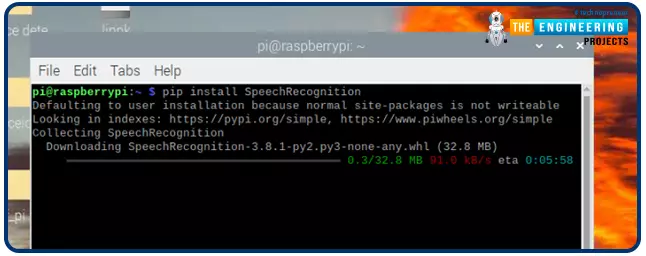

$ pip set up SpeechRecognition
If you’ve accomplished the setup, you need to begin a command line window and kind:

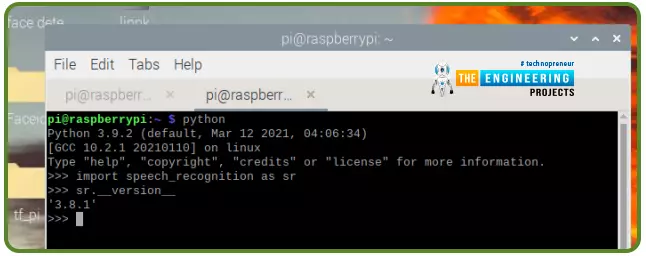
Import speech_recognition as sr
Sr.__version__
Let’s depart this window open for now. Quickly sufficient, you can use it.
In the event you solely must cope with pre-existing audio recordings, Speech Recognition will work straight out of the field. Just a few stipulations are required for some use instances, although. Specifically, the PyAudio library should report audio from a mic.
As you proceed studying, you will uncover which elements you require. In the intervening time, let’s take a look at the package deal’s fundamentals.
Recognizer Class
The recognizer is on the coronary heart of Speech Recognition’s magic.
Naturally, the basic perform of a Recognizer class is to acknowledge spoken phrases and phrases. Every occasion has a variety of choices for figuring out voice from the enter audio.
The method of establishing a Recognizer is simple. It is so simple as typing “in your energetic interpreter window.”

sr.Recognizer()
There are seven methods to acknowledge the voice from enter audio by using a definite utility programming interface in every Recognizer class. The next are examples:

Other than recognizing sphinx(), all the opposite capabilities fail to work offline utilizing CMU Sphinx. Web entry is required for the remaining six actions.
This tutorial doesn’t cowl all the capabilities and options of each Software programming interface intimately. Speech Recognition comes with a preset utility programming interface key for the Google Speech Software programming interface, permitting you to right away stand up and operating with the service. Because of this, this tutorial will extensively use the Internet Speech Software programming interface. Solely the Software programming interface key and the person are required for the remaining six utility programming interfaces.
Speech Recognition offers a default utility programming interface key for testing causes solely, and Google reserves the appropriate to cancel it at any time. Utilizing the Google Internet utility programming interface in a manufacturing setting is just not really helpful. There isn’t any methodology to extend the every day request quota, even when you have a legitimate utility programming interface key. In the event you learn to use the Speech Recognition utility programming interface at the moment, it is going to be simple to use to any of your tasks.
At any time when a acknowledge perform fails to acknowledge the voice, it would output an error message. Request Error if the appliance programming interface is unavailable. A defective Sphinx set up may trigger this within the case of recognizing sphinx(). If quotas are exceeded, servers are unreachable, or there is not web service, a Request Error shall be raised for all of the six strategies.
Allow us to use acknowledge google() in our interpreter window and see if it really works!

Precisely what has transpired?
One thing like that is most probably what you’ve got gotten.

I am positive you may have foreseen this. How is it doable to inform one thing from nothing?
The Recognizer perform acknowledge() expects an audio knowledge parameter. In the event you’re utilizing Speech Recognition, then audio knowledge ought to change into an occasion of the audio knowledge class.
To assemble an AudioData occasion, you’ve two choices: you’ll be able to both use an audio file or report your audio. We’ll start with audio information as a result of they’re less complicated to work with.
Utilizing Audio Information
To proceed, you have to first get hold of and save an audio file. Use the identical location the place your Python interpreter is operating to retailer the file.
Speech Recognition’s AudioFile interface permits us to work with audio information simply. As a context supervisor, this class provides the power to entry the data of an audio file by offering a path to its location.
File Codecs which might be supported
This software program helps varied file codecs, which embody:



You will must come up with the FLAC command line and a FLAC encoding instrument.
Recording knowledge utilizing the report() Perform
To play the “har.wav” file, enter the next instructions into your interpreter window:

har = sr.AudioFile(‘har.wav’)
with harvard as supply:
audio = r.report(supply)
Utilizing the AudioFile class supply, the context supervisor shops the information learn from the file. Then, utilizing the report() perform, the complete file’s knowledge is saved to an AudioData class. Confirm this by trying on the format of the audio:

sort(audio)
Now you can use recognize_google() to see if any voice will be discovered within the audio file. You may need to attend a couple of seconds for the output to seem, based mostly on the pace of your broadband connection.

r.recognize_google(audio)
Congratulations! You’ve got simply completed your very first audio transcription!
Inside the “har.wav” file, you will discover situations of Har Phrases in the event you’re curious. In 1965, the IEEE issued these phrases to judge phone traces for voice intelligibility. VoIP and telecom testing proceed to utilize them these days.
Seventy-two lists of 10 phrases are included within the Har Phrases. On the Open Voice Repository webpage, you will uncover a free recording of those phrases and phrases. Every language has its personal set of translations for the recordings. Put your code by way of its paces; they provide many free sources.
Segments with a begin and finish time
Chances are you’ll need to report a small part of the speaker’s speech. The report() methodology accepts the period time period parameter, which terminates this system after an outlined period of time.
Utilizing the instance above, the primary 4 secs of the file shall be saved as a transcript.

with har as supply:
audio = r.report(supply, period=4)
r.recognize_google(audio)
Within the information stream, make the most of the report() perform inside a block. Because of this, the 4 secs of audio you recorded for 4 seconds shall be returned whenever you report for 4 seconds once more.

with har as supply:
audio1 = r.report(supply, period=4)
audio2 = r.report(supply, period=4)
r.recognize_google(audio1)
r.recognize_google(audio2)
As you’ll be able to see, the third phrase is contained inside audio2. When a timeframe is specified, the recorder can stop in the course of a phrase. This could hurt the transcript. Within the meantime, here is what I’ve to say about this.
The offset key phrases arguments will be handed to the report() perform mixed with a recording interval. Earlier than recording, this setting specifies what number of frames of a file to ignore.

with har as supply:
audio = r.report(supply, offset=4, period=3)
r.recognize_google(audio)
Utilizing the period and the offset phrase parameters may also help you section an audio monitor in the event you perceive the language construction beforehand. They’ll, nevertheless, be misused if used hurriedly. Utilizing the next command in your interpreter ought to get the specified end result.

with har as supply:
audio = r.report(supply, offset=4.7, period=2.8)
r.recognize_google(audio)
The appliance programming interface solely acquired “akes warmth,” which matches “Mesquite,” as a result of “it t” half of the sentence was missed.
You additionally recorded “a co,” the primary phrase of the third phrase after the recording. The appliance programming interface matched this to “Aiko.”
One other doable clarification for the inaccuracy of your transcriptions is human error. Noise! Because the audio is comparatively clear, the situations talked about above all labored. Noise-free audio can’t be anticipated within the precise world besides if the soundtracks will be processed upfront.
Noise Can Have an effect on Speech Recognition.
Noise is an unavoidable a part of on a regular basis existence. All audiotapes have some noise stage, and speech recognition applications can endure if the noise is not correctly dealt with.
I listened to the “jackhammer” audio pattern to grasp how noise can impair speech recognition. Guarantee to put it aside to the foundation folder of your interpreter session.
The sound of a jackhammer is heard within the background whereas the phrases “the stale scent of previous beer stays” are spoken.
Attempt to translate this file and see what unfolds.

jackmer = sr.AudioFile(‘jackmer.wav’)
with jackhammer as supply:
audio = r.report(supply)
r.recognize_google(audio)
How fallacious!
So, how do you go about coping with this case? The Recognizer class has an alter for ambient noise() perform you would possibly need to give a shot.

with jackmer as supply:
r.adjust_for_ambient_noise(supply)
audio = r.report(supply)
r.recognize_google(audio)
You are getting nearer, but it surely’s nonetheless not fairly there but. As well as, the assertion’s first phrase is lacking: “the.” How come?
Recognizer calibration is completed by studying the primary seconds of the audio stream and adjusting for noise stage. Because of this, the stream has already been consumed whenever you run report() to report the information.
Adjusting ambient noise() takes the period phrase parameter to alter the time-frame for evaluation. The default worth for this parameter is 1, however you’ll be able to change it to no matter you select. Scale back this worth by half.

with jackmer as a supply:
r.adjust_for_ambient_noise(supply, period=0.5)
audio = r.report(supply)
r.recognize_google(audio)
Now you’ve got obtained an entire new set of issues to cope with after getting “the” at first of the sentence. There are occasions when the noise cannot be faraway from the sign as a result of it merely has lots of noise to deal with. That is the case on this explicit file.
These issues could necessitate some sound pre-processing in the event you encounter them usually. Audio enhancing applications, which may add filters to the audio, can be utilized to perform this. In the intervening time, know that background noise could cause points and must be dealt with to enhance voice recognition accuracy.
Software programming interface responses is likely to be helpful at any time when working with noisy information. There are numerous methods to parse the JSON textual content returned by most utility programming interfaces. For the acknowledge google() perform to supply probably the most correct transcription, you have to explicitly request it.
Utilizing the acknowledge google() perform and the present all boolean argument will do that.
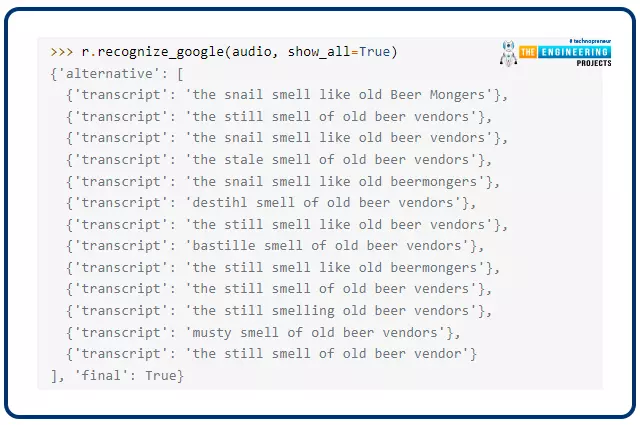
r.recognize_google(audio, show_all=True)
A transcript record will be discovered within the dictionary returned by recognizing google(), with the entry ‘various .’This response format varies in several utility programming interfaces, but it surely’s primarily helpful for debugging functions whenever you get it.
As you’ve got seen, the Speech Recognition software program has rather a lot to supply. Other than gaining experience with the offsets and period arguments, you additionally discovered concerning the dangerous results noise has on transcription accuracy.
The enjoyable is about to start. Make your challenge dynamic by utilizing a mic as a substitute of transcribing audio clips that do not require any enter from the person.
Utilizing Microphone

For Speech Recognizer to work, you have to get hold of the PyAudio library.
Set up PyAudio
Use the command under to put in pyaudio in raspberry pi:

sudo apt-get set up python-pyaudio python3-pyaudio
Affirmation of Profitable Setup
Utilizing the console, you’ll be able to confirm that PyAudio is working correctly.

python -m speech_recognition
Guarantee your mic is turned on and unmuted. That is what you will see if every little thing went in response to plan:

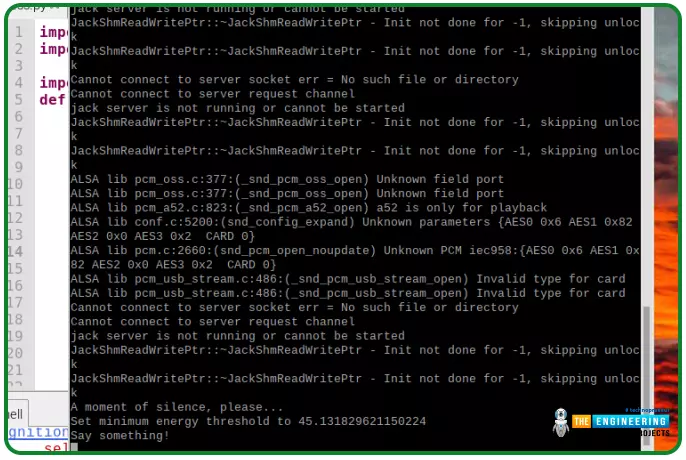
Let SpeechRecognition translate your voice by speaking into your mic and discovering its accuracy.
Microphone occasion
The recognizer class ought to be created in a separate interpreter window.

import speech_recognition as sr
r = sr.Recognizer()
After using an audio recording, you will use the system mic as your enter. Instantiation your Microphone interface to get at this data!

mic = sr.Microphone()
For raspberry pi, you have to present a tool’s index to make use of a sure mic. For a listing of microphones, merely name our Mic class perform.

Sr.Microphone.list_microphone_names()
Understand that the outcomes could range from these proven within the examples.
Chances are you’ll discover the mic’s system index utilizing the record microphone names perform. A mic occasion would possibly seem like this in the event you wished to make use of the “entrance” mic, which has a worth of Three within the output.
mic = sr.Microphone(device_index=3)
Use pay attention() to report the audio from the mic
A Mic occasion is prepared, so let’s get began recording.
Much like AudioFile, Mic serves as a context supervisor for the appliance. The pay attention() perform of the Recognizer interface can be utilized within the with part to report audio from the mic. This method makes use of an enter supply as its preliminary parameter to seize audio till quiet is invoked.

with mic as supply:
audio = r.pay attention(supply)
Strive saying “hello” into your mic as soon as you’ve got accomplished the block. Please be affected person because the interpreter prompts reappear. When you hear the “>>>” immediate once more, you need to have the ability to hear the voice.

r.recognize_google(audio)
If the message by no means seems once more, your mic might be taking over the extreme background noise. Ctrl then C key can halt the execution and restore your prompts.
Recognizer class’s adjustment of ambient noise() methodology have to be used to cope with the noise stage, very like you probably did whereas trying to decipher the noisy audio monitor. It is sensible to do that everytime you’re listening for mic enter as a result of it is much less unpredictable than audio file sources.

with mic as supply:
r.adjust_for_ambient_noise(supply)
audio = r.pay attention(supply)
Permit for adjustment of ambient noise() to complete earlier than talking “good day” into the mic after executing the code talked about above. Be affected person because the interpreter’s prompts reappear earlier than ascertaining the speech.
Understand that the audio enter is analyzed for a second by adjusting ambient noise(). Utilizing the period parameter, you’ll be able to shorten it if essential.
In keeping with the web site, not underneath 0.5 secs is really helpful by the Speech Recognition specification. There are occasions when better durations are simpler. The decrease the ambient noise, the decrease the worth you want. Sadly, this data is usually omitted of the event course of. For my part, the default one-second period is enough for many functions.
How one can deal with speech that is not recognizable?
Utilizing your interpreter, sort within the above code snippet and mutter something nonsensical into the mic. Chances are you’ll anticipate a response akin to this:
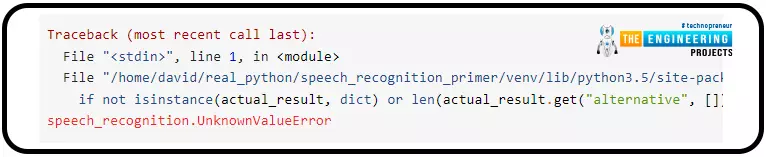
An UnknownValueError exception is thrown if the appliance programming interface can not translate speech into textual content. You could all the time encapsulate utility programming interface requests in attempt to besides statements to deal with this drawback.
Getting the exception thrown could take extra effort than you think about. In relation to transcribing vocal sounds, the API places in lots of effort and time. For me, even the tiniest of noises had been translated into phrases like “how.” A cough, claps of the palms, or clicking the tongue would all elevate an exception.
A “Guess the Phrase” sport to Put every little thing collectively
To place what you’ve got discovered from the SpeechRecognition library into apply, develop a easy sport that randomly selects a phrase from a set of phrases and permits the participant three tries to guess it.


Listed under are all the scripts:
import random
import time
import speech_recognition as sr
def recognize_speech_from_mic(recognizer, microphone):
if not isinstance(recognizer, sr.Recognizer):
elevate TypeError(“`recognizer` have to be `Recognizer` occasion”)
if not isinstance(microphone, sr.Microphone):
elevate TypeError(“`microphone` have to be `Microphone` occasion”)
with microphone as supply:
recognizer.adjust_for_ambient_noise(supply)
audio = recognizer.pay attention(supply)
response = {
“success”: True,
“error”: None,
“transcription”: None
}
strive: response[“transcription”] = recognizer.recognize_google(audio)
besides sr.RequestError:
response[“success”] = False
response[“error”] = “API unavailable”
besides sr.UnknownValueError:
response[“error”] = “Unable to acknowledge speech”
return response
if __name__ == “__main__”:
WORDS = [“apple”, “banana”, “grape”, “orange”, “mango”, “lemon”]
NUM_GUESSES = 3
PROMPT_LIMIT = 5
recognizer = sr.Recognizer()
microphone = sr.Microphone()
phrase = random.alternative(WORDS)
directions = (
“I am considering of one among these phrases:n”
“{phrases}n”
“You’ve {n} tries to guess which one.n”
).format(phrases=”, “.be a part of(WORDS), n=NUM_GUESSES)
print(directions)
time.sleep(3)
for i in vary(NUM_GUESSES):
for j in vary(PROMPT_LIMIT):
print(‘Guess {}. Communicate!’.format(i+1))
guess = recognize_speech_from_mic(recognizer, microphone)
if guess[“transcription”]:
break
if not guess[“success”]:
break
print(“I did not catch that. What did you say?n”)
if guess[“error”]:
print(“ERROR: {}”.format(guess[“error”]))
break
print(“You stated: {}”.format(guess[“transcription”]))
guess_is_correct = guess[“transcription”].decrease() == phrase.decrease()
user_has_more_attempts = i < NUM_GUESSES – 1
if guess_is_correct:
print(“Right! You win!”.format(phrase))
break
elif user_has_more_attempts:
print(“Incorrect. Strive once more.n”)
else:
print(“Sorry, you lose!nI was considering of ‘{}’.”.format(phrase))
break
Let’s analyze this just a little bit additional.
There are three keys to this perform: Recognizer and Mic. It takes these two as inputs and outputs a dictionary. The “success” worth signifies the success or failure of the appliance programming interface request. It’s doable that the 2nd key, “error,” is a notification exhibiting that the appliance programming interface is inaccessible or {that a} person’s speech was incomprehensible. As a remaining contact, the audio enter “transcription” key features a translation of all the captured audio.
A TypeError is raised if the popularity system or mic parameters are invalid:

Utilizing the pay attention() perform, the mic’s sound is recorded.
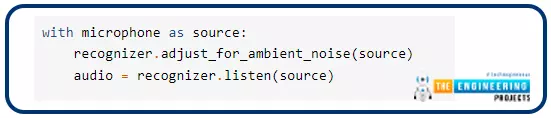
For each name to acknowledge speech from the mic(), the recognizer is re-calibrated utilizing the alter for ambient noise() approach.
After that, whether or not there’s any voice within the audio, acknowledge perform is invoked to translate it. RequestError and UnknownValueError are caught by the attempt to besides block and handled accordingly. Recognition of voice from a microphone returns a dictionary containing the success, error, and translated voice of the appliance programming interface request and the dictionary keys.
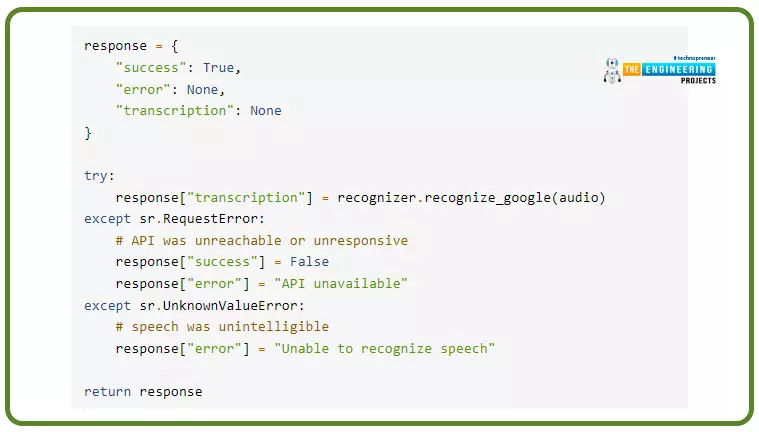
In an interpreter window, execute the next code to see if the perform works as anticipated:

import speech_recognition as sr
from guessing_game import recognize_speech_from_mic
r = sr.Recognizer()
m = sr.Microphone()
recognize_speech_from_mic(r, m)
The precise gameplay is kind of primary. An preliminary set of phrases, a most of guesses permitted, and a time restriction are established:

As soon as that is accomplished, a random phrase is chosen from the record of WORDS and enter into the Recognizer and Mic situations.

After displaying some instructions, the situation assertion is utilized to deal with every person’s makes an attempt at guessing the chosen phrase. That is the primary operation that occurs within the primary loop. One other loop tries to establish the individual’s guesses no less than PROMPT LIMIT situations and shops the dictionary offered to a variable guess.
In any other case, a translation was carried out, and the closed-loop will finish with a break in case the guess “transcription” worth is unknown. False is about as an utility programming interface error when no audio is transcribed; this causes the loop to be damaged once more with a break. Other than that, the appliance programming interface request was profitable; nonetheless, the speech was unintelligible. As a precaution, the for loop repeatedly warns the person, giving them a second likelihood to succeed.
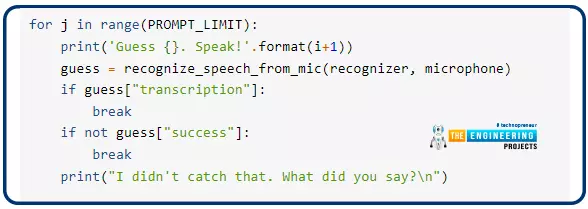
If there are any errors contained in the guess dictionary, the inside loop shall be terminated once more. An error discover shall be printed, and a break is used to exit the outer for loop, which can cease this system execution.

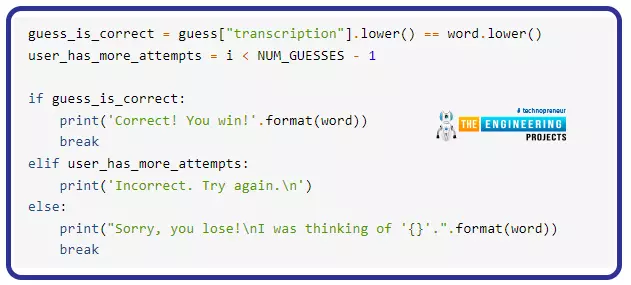
Transcriptions are checked for accuracy by evaluating the entered textual content to a phrase drawn at random. Because of this, the decrease() perform for textual content objects is employed to make sure a extra correct prediction. On this case, it would not matter if the appliance programming interface returns “Apple” or “apple” because the speech matching the phrase “apple.”
If the person’s estimate was right, the sport is over, they usually have gained. The outermost loop restarts when an individual guesses incorrectly and a contemporary guess is discovered. In any other case, the person shall be eradicated from the competition.
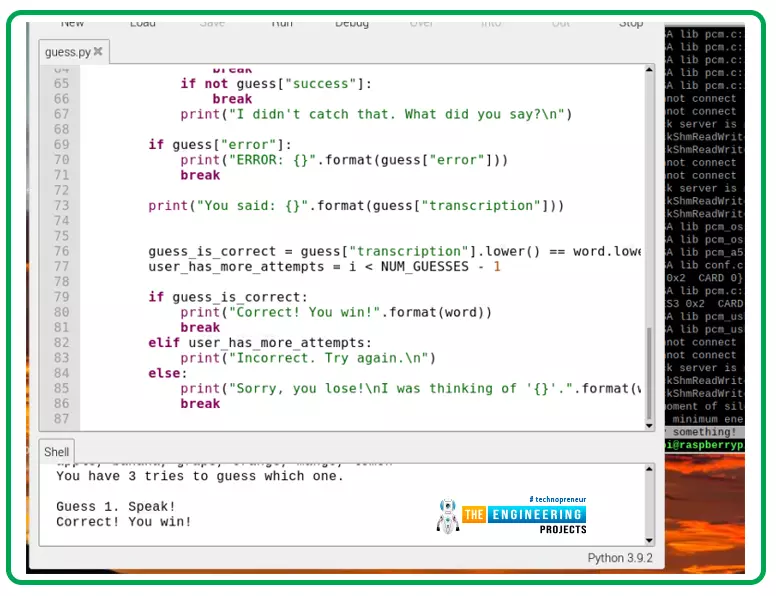
That is what you will get whenever you run this system:
Recognition of Different Languages
Speech recognition in different languages, however, is solely doable and extremely easy.
The language parameter have to be set to the required string to make use of the acknowledge() perform in a language aside from English.

r = sr.Recognizer()
with sr.AudioFile(‘path/to/audiofile.wav’) as supply:
audio = r.report(supply)
r.recognize_google(audio, language=”fr-FR”)
There are just a few strategies that accept-language key phrases:

What are the purposes of speech recognition software program?
-
Cellular Cost with Voice command
Do you ever have second ideas about how you are going to pay for future purchases? Has it occurred to you that, sooner or later, you could possibly pay for items and providers just by talking? There is a good likelihood that can occur quickly! A number of firms are already creating voice instructions for cash transfers.
This technique means that you can converse a one-time passcode quite than getting into a passcode earlier than shopping for the product. In relation to on-line safety, consider captchas and different one-time passwords which might be learn aloud. It is a significantly higher choice than reusing a password each time. Quickly, voice-activated cellular banking shall be broadly used.
-
AI Assistants
When driving, it’s possible you’ll use such Clever techniques to get navigation, carry out a Google search, begin a playlist of songs, and even activate the lights in your house with out touching your gadget. These digital assistants are programmed to reply to each voice activation, whatever the person.
There are new applied sciences that allow Ai purposes to acknowledge particular person customers. This tech, as an example, permits it to reply to the voice of a sure individual completely. Utilizing an iPhone for example, it has been round for a couple of years now. If you’d like Siri to solely reply to your instructions and queries whenever you converse to it, you are able to do so in your iPhone. Unauthorized entry to your devices, data, and property is much much less doable when your voice can solely activate your Synthetic clever assistant. Anybody who is just not permitted to make use of the assistant will be unable to activate it. Different makes use of for this expertise are nearly in all probability on the horizon.
-
Translation Software
In a distant place, think about trying to test into an unfamiliar lodge. Since neither you nor the entrance desk worker is fluent within the different nation’s language, nobody is obtainable to behave as a translator. You should use the translator system to speak into the microphone and have your speech processed and translated verbally or graphically to speak with one other individual.
Moreover, this tech can profit multinational enterprises, instructional establishments, or different establishments. You’ll be able to have a extra productive dialog with anybody who would not converse your language, which helps break down the linguistic barrier.
Conclusion
There are lots of methods to make use of the SpeechRecognition program, together with putting in it and using its Recognizer interface, which can be used to acknowledge audio from each information and the mic. You discovered the right way to use the report offset and the period key phrases to extract segments from an audio recording.
The recognizer’s tolerance to noise stage will be adjusted utilizing the alter for the ambient noise perform, which you’ve got seen in motion. Recognizer situations can throw RequestErrors and UnknownValueErrors, and you have discovered the right way to handle them with attempt to besides block.
Extra will be discovered about speech recognition than what you’ve got simply learn. We’ll implement the RTC module integration in our upcoming tutorial to allow real-time management.





